

Voice Assistant Bots leverage AI, speech recognition, and AR to provide real-time, multilingual, and personalized interactions. From enterprise productivity to retail and healthcare, they streamline tasks, enhance engagement, and transform how humans communicate with technology.
Understanding Voice Assistant Bots: The Future of Interaction
Voice Assistant Bots have become an integral part of how humans interact with technology today. From smartphones to smart homes, these intelligent systems are designed to understand spoken language and respond in ways that feel natural. Unlike traditional software that requires manual input through keyboards or touchscreens, Voice Assistant Bots allow users to communicate verbally, making interactions faster, more intuitive, and often more engaging.
At the core of every Voice Assistant Bot is a combination of natural language processing (NLP), machine learning, and speech recognition. These components work together to convert spoken words into actionable commands, interpret user intent, and provide appropriate responses. The result is a seamless user experience where technology feels more like a conversation partner than a mere tool.
The Early Evolution of Voice Assistants
The concept of Voice Assistant Bots isn’t new. Early attempts at speech recognition date back to the 1950s, when systems could recognize only a few spoken words. Over the decades, technological advancements in computing power, algorithms, and data storage paved the way for more sophisticated systems. By the 2000s, voice-enabled software began appearing in consumer electronics, allowing users to perform basic tasks like dialing a phone number or setting reminders.
With the rise of artificial intelligence, Voice Assistant Bots have evolved from simple command-based systems to intelligent assistants capable of context-aware conversations. Today’s bots can handle complex queries, provide personalized recommendations, and even engage in multiturn dialogues, making them indispensable in both personal and professional contexts.
Key Components of Voice Assistant Bots
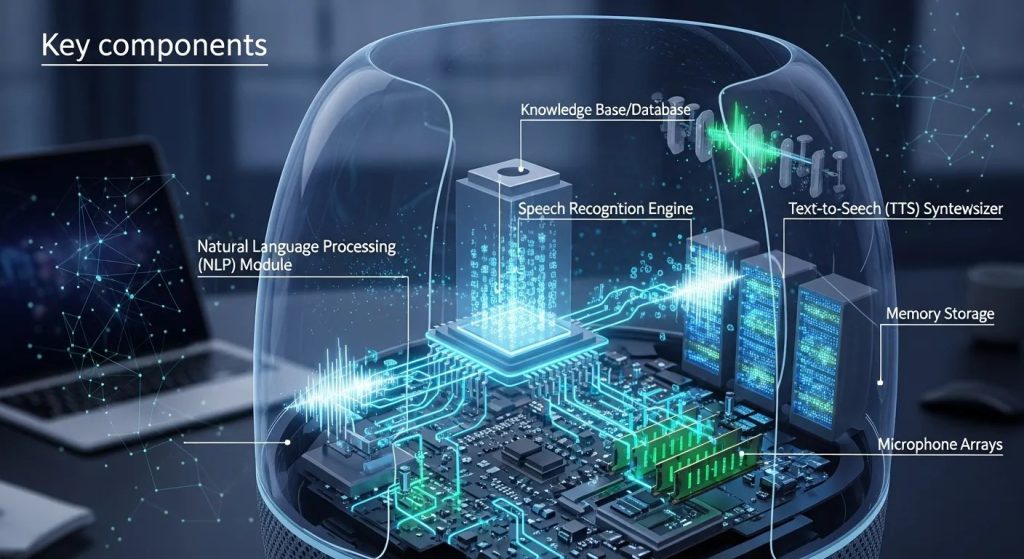
To understand how these bots work, it’s helpful to break down their primary components:
- Speech Recognition Engine – Converts spoken words into text using advanced acoustic modeling.
- Natural Language Understanding (NLU) – Interprets the meaning behind the words, identifying intent and context.
- Dialogue Management – Determines the appropriate response based on user input and conversation history.
- Text-to-Speech (TTS) Engine – Converts the bot’s response into natural-sounding speech.
These components work in harmony to create a fluid interaction. For example, when a user asks a Voice Assistant Bot about the weather, the system first transcribes the spoken words, analyzes them for intent, retrieves relevant information, and finally responds audibly in a natural tone.
Real-World Applications
Voice Assistant Bots are no longer confined to smartphones. They are transforming multiple industries and applications:
- Smart Homes: Users can control lights, thermostats, and appliances using voice commands.
- Healthcare: Voice-enabled systems help doctors with patient record management and diagnostics.
- Customer Service: Companies integrate bots to provide instant responses to inquiries, reducing wait times and improving efficiency.
Even in marketing, innovative businesses are combining Voice Assistant Bots with a Lead Generation Chatbot, enabling conversational engagement that guides potential customers through sales funnels seamlessly. This approach blends traditional AI-powered lead generation with the conversational intelligence of voice assistants, enhancing both user experience and conversion rates.
Types of Voice Assistant Bots
Voice Assistant Bots come in various forms, tailored to specific user needs and environments. Understanding these types helps businesses and users select the right solutions for their objectives.
Personal Voice Assistants
Personal assistants are perhaps the most familiar type of Voice Assistant Bots. They live on smartphones, smart speakers, or wearable devices and focus on helping individuals manage daily tasks. These bots can schedule appointments, send messages, provide weather updates, or even control home devices. The intelligence behind these assistants relies on deep learning algorithms that learn user preferences over time, improving the relevance and accuracy of responses.
Enterprise Voice Assistants
In professional settings, Voice Assistant Bots are being increasingly deployed to streamline workflows and enhance productivity. These systems often integrate with enterprise software like CRMs, HR platforms, and project management tools. Employees can request real-time data updates, generate reports, or manage meetings using simple voice commands, minimizing the friction of manual inputs. Many enterprises now leverage Voice Enabled Chatbots to extend conversational interfaces across multiple departments, ensuring consistent and efficient communication with both employees and clients.
Customer Service and Support Bots
Companies are also integrating Voice Assistant Bots into customer service channels. These bots handle common inquiries, troubleshoot issues, and escalate complex queries to human agents. Unlike traditional call centers, voice bots can operate 24/7, providing instant responses and reducing operational costs. By analyzing user intent and sentiment, these bots ensure that customer interactions feel personalized rather than robotic, enhancing brand loyalty and satisfaction.
AI Models Behind Voice Assistant Bots
The intelligence of modern Voice Assistant Bots comes from sophisticated AI models that process language, speech, and context. Some of the key technologies include:
- Automatic Speech Recognition (ASR): Converts spoken language into text, enabling bots to interpret human speech accurately.
- Natural Language Processing (NLP): Breaks down text to understand grammar, syntax, and semantics.
- Machine Learning Models: Continuously improve understanding and predictions based on interactions and user behavior.
- Contextual AI: Helps bots maintain conversation context across multiple turns, ensuring more natural and human-like interactions.
These models often require massive datasets to train effectively. Companies invest in diverse voice samples, multilingual speech datasets, and real-world conversational logs to enhance the accuracy and adaptability of their bots.
Technological Breakthroughs in Voice Assistance
Over the past decade, Voice Assistant Bots have benefited from breakthroughs in AI, cloud computing, and hardware capabilities:
- Edge AI Processing: Allows some voice processing to happen directly on devices, improving speed and privacy.
- Multilingual Support: AI models can now understand and respond in multiple languages, making them accessible to a global audience.
- Emotion and Sentiment Detection: Advanced bots can detect tone and sentiment, adapting responses accordingly.
- Integration with IoT Devices: Voice assistants can seamlessly control a wide range of connected devices, from smart lights to advanced medical equipment.
These innovations are enabling businesses to deploy more sophisticated voice systems. For example, retail companies can combine voice technology with personalized shopping experiences, while healthcare providers can offer voice-driven diagnostic support.
Multilingual Capabilities of Voice Assistant Bots

As businesses and users become increasingly global, the ability for Voice Assistant Bots to operate across multiple languages is no longer optional it’s essential. AI Multilingual Bots have emerged to meet this demand, enabling seamless communication with users regardless of their native language.
These bots use advanced natural language processing models trained on vast datasets spanning dozens of languages. Beyond mere translation, they understand regional dialects, colloquialisms, and context-specific meanings. For instance, the word “football” might mean different sports in the United States and the United Kingdom. A truly multilingual bot recognizes these nuances and tailors responses accordingly, ensuring accurate and culturally sensitive interactions.
How AI Learns Multiple Languages
Training AI Multilingual Bots requires sophisticated approaches:
- Transfer Learning: Models trained on one language are adapted to understand another, leveraging shared linguistic patterns.
- Large-Scale Corpora: Massive text and speech datasets in multiple languages are essential for accurate recognition and response generation.
- Contextual Understanding: AI systems learn to interpret sentences not just word by word, but based on overall intent, cultural context, and prior interactions.
- Continuous Learning: These bots improve over time by analyzing real-world conversations and user feedback, refining their multilingual capabilities.
The result is a bot that can switch languages seamlessly or even handle mixed-language queries in a single conversation. This capability is invaluable for global companies looking to maintain consistent customer support and engagement.
Industry Applications of Voice Assistant Bots
Voice Assistant Bots are transforming multiple industries by automating tasks, improving efficiency, and enhancing user experience:
Healthcare
Healthcare providers use Voice Assistant Bots to streamline patient management. Patients can schedule appointments, receive reminders, or inquire about symptoms. Multilingual support ensures that healthcare services are accessible to a diverse population, breaking down language barriers that could affect care quality.
Retail and E-commerce
Retailers leverage Voice Assistant Bots for personalized shopping experiences. Users can ask about product availability, get recommendations, and even complete transactions through voice commands. AI Multilingual Bots expand reach to international customers, providing consistent, accurate, and natural interactions regardless of language.
Banking and Finance
Banks are integrating Voice Assistant Bots into customer service channels to provide account information, verify transactions, and assist with financial planning. Multilingual capabilities ensure compliance with regional regulations and cater to a diverse customer base.
Education
Educational institutions deploy multilingual voice bots to assist students with administrative tasks, study guidance, and learning new languages. These bots also provide personalized tutoring, responding intelligently to questions and adjusting difficulty based on learner performance.
The Role of AI in Improving Accuracy
The efficiency of Voice Assistant Bots relies heavily on the AI models driving them. Deep learning techniques, such as transformer architectures and recurrent neural networks, help bots understand syntax, context, and user intent. Combined with continual learning, these systems improve in precision over time, reducing misunderstandings and enhancing user satisfaction.
By integrating AI, businesses can deploy Voice Assistant Bots that not only communicate effectively but also learn from every interaction, becoming smarter, faster, and more reliable with each conversation.
Enhancing User Experience with Voice Assistant Bots

One of the most powerful aspects of modern Voice Assistant Bots is their ability to provide real-time support, transforming the way businesses interact with customers. Gone are the days when users had to wait on hold or navigate complex phone menus. Today’s intelligent voice systems offer instant responses, personalized guidance, and context-aware interactions.
Integrating Live Support
Many organizations combine automated voice assistance with Live Chatbot Support, creating a hybrid system that maximizes both efficiency and human touch. For routine inquiries, the bot can handle tasks autonomously, freeing human agents to focus on complex issues. If the system detects a problem that requires human intervention, it seamlessly transfers the conversation, ensuring users never feel abandoned.
This integration improves response times, reduces operational costs, and enhances overall satisfaction. For example, e-commerce companies can provide instant assistance for order tracking, returns, or payment issues, while technical support teams can use voice bots to troubleshoot software or hardware problems efficiently.
Real-Time Assistance and Multitasking
Voice Assistant Bots excel in scenarios requiring real-time assistance. In professional environments, employees can request live updates, schedule meetings, or retrieve documents without interrupting their workflow. In healthcare, doctors can query patient records verbally while performing other tasks, ensuring efficiency and accuracy.
The adaptability of these bots is amplified by AI-driven predictive analytics. By analyzing prior interactions and user behavior, Voice Assistant Bots can anticipate needs, suggest relevant actions, and even pre-fill responses. This proactive approach significantly enhances user experience, making interactions feel natural and intuitive.
Use Cases Across Industries
Customer Service
Customer-facing industries benefit tremendously from combining Voice Assistant Bots with live support. Companies can maintain 24/7 availability, answer common questions, and resolve issues promptly, boosting loyalty and engagement.
Enterprise Productivity
In corporate settings, employees rely on voice assistants for administrative tasks such as managing calendars, sending emails, or retrieving reports. By automating repetitive tasks, Voice Assistant Bots save time and reduce errors.
Retail and Hospitality
Retailers and hospitality businesses use voice bots to assist customers in real time checking product availability, booking reservations, or offering personalized recommendations. Integrating live support ensures that complex requests are handled seamlessly, enhancing the customer journey.
Technical and IT Support
Technical teams often deploy voice bots to troubleshoot devices or software. A bot can guide users step-by-step, provide diagnostic instructions, or escalate issues to human experts when necessary. This reduces downtime and increases user satisfaction.
Psychological Impact on Users
The combination of real-time assistance and personalized interaction has a psychological effect on users. It builds trust, reduces frustration, and makes technology feel approachable. Unlike traditional automated systems, Voice Assistant Bots create a sense of conversational engagement, which encourages more frequent and meaningful interactions.
By offering Live Chatbot Support alongside voice capabilities, businesses can ensure that users feel supported at every step. This hybrid approach balances automation with human empathy, fostering loyalty and long-term engagement.
Emerging Technologies in Voice Assistant Bots

As Voice Assistant Bots continue to evolve, they are increasingly integrated with cutting-edge technologies like augmented reality (AR) and advanced AI systems. This convergence allows users to interact not just through voice, but also visually, creating immersive experiences that go beyond traditional interfaces.
AI-Powered AR Vision
One of the most exciting innovations is AI-Powered AR Vision, which combines voice commands with augmented reality overlays. For example, in retail, a customer can ask a voice assistant to show how furniture fits in a room. The bot uses AR to project a virtual image of the product, while AI ensures that the visualization aligns perfectly with the room’s dimensions.
Similarly, in healthcare, surgeons can leverage AI-Powered AR Vision with voice commands to access patient scans, highlight critical areas, or receive real-time guidance during procedures. This hands-free integration enhances precision and safety, demonstrating the transformative potential of combining voice and visual intelligence.
AR Facial Tracking
Another breakthrough is AR Facial Tracking, which uses AI and computer vision to detect and analyze facial movements. Voice Assistant Bots equipped with this technology can personalize interactions based on user expressions or emotions. For instance, if a user appears confused, the bot can offer additional guidance or simplify instructions.
In marketing and retail, AR Facial Tracking enables personalized promotions or recommendations. A store kiosk might detect a smiling customer and suggest popular products, or a learning platform might adjust content based on engagement levels, all while responding to voice commands seamlessly.
Enhancing Interaction Through Multimodal Interfaces
The integration of voice with AR and visual cues creates multimodal interfaces, where users can combine speech, gestures, and visual attention to communicate with systems more naturally. This approach reduces cognitive load, allowing users to focus on tasks instead of figuring out how to operate technology.
For example:
- Smart Home Control: Users can point at a device and ask a Voice Assistant Bot to adjust settings.
- Education: Students can interact with 3D models using both voice and gesture commands.
- Industrial Applications: Engineers can examine machinery with AR overlays while receiving voice-guided instructions for maintenance.
The Role of AI in Multimodal Systems
AI is the backbone of these advanced voice-integrated AR systems. It processes voice commands, interprets visual input, tracks context, and makes predictions about user intent. Machine learning models ensure continuous improvement, allowing systems to adapt to individual preferences and environmental changes.
By merging Voice Assistant Bots with AI-Powered AR Vision and AR Facial Tracking, businesses can deliver highly interactive, efficient, and personalized experiences. This convergence is setting new standards in user engagement and operational efficiency across industries.
Future Potential
The combination of voice, AI, and AR is only beginning to show its potential. We can expect:
- Enhanced Accessibility: Multimodal interfaces make technology accessible to users with disabilities, allowing them to navigate complex systems via voice and visual cues.
- Smarter Retail Experiences: Retailers can provide fully interactive shopping experiences, blending physical products, virtual displays, and voice guidance.
- Advanced Remote Collaboration: Teams can collaborate virtually in AR environments while communicating naturally through Voice Assistant Bots, improving productivity and reducing misunderstandings.
Conclusion
Voice Assistant Bots are reshaping the way humans interact with technology, combining voice recognition, AI intelligence, and even AR integration to create seamless, intuitive experiences. From personal assistants to enterprise solutions, these bots enhance efficiency, accessibility, and engagement across industries. Innovations like AI-Powered AR Vision and AR Facial Tracking demonstrate how voice interfaces are evolving beyond simple commands into multimodal, context-aware systems. By integrating features such as Live Chatbot Support and multilingual capabilities, businesses can deliver personalized, real-time assistance. As technology advances, Voice Assistant Bots will continue to redefine productivity, customer experience, and human-computer interaction worldwide.
Frequently Asked Questions (FAQ)
What are Voice Assistant Bots?
Voice Assistant Bots are AI-powered systems that understand spoken language, process user intent, and provide relevant responses, enabling natural voice-based interactions.
How do Voice Assistant Bots work?
They use speech recognition, natural language processing, dialogue management, and text-to-speech technology to interpret commands and respond accurately.
What industries benefit from Voice Assistant Bots?
Healthcare, retail, finance, education, and enterprise operations all leverage these bots for efficiency, customer support, and enhanced engagement.
Can Voice Assistant Bots support multiple languages?
Yes, AI Multilingual Bots allow them to understand and respond accurately across different languages and dialects.
Are Voice Assistant Bots safe and secure?
Modern bots use encryption, access controls, and privacy safeguards, but businesses must follow best practices to protect sensitive data.








{kind=link}